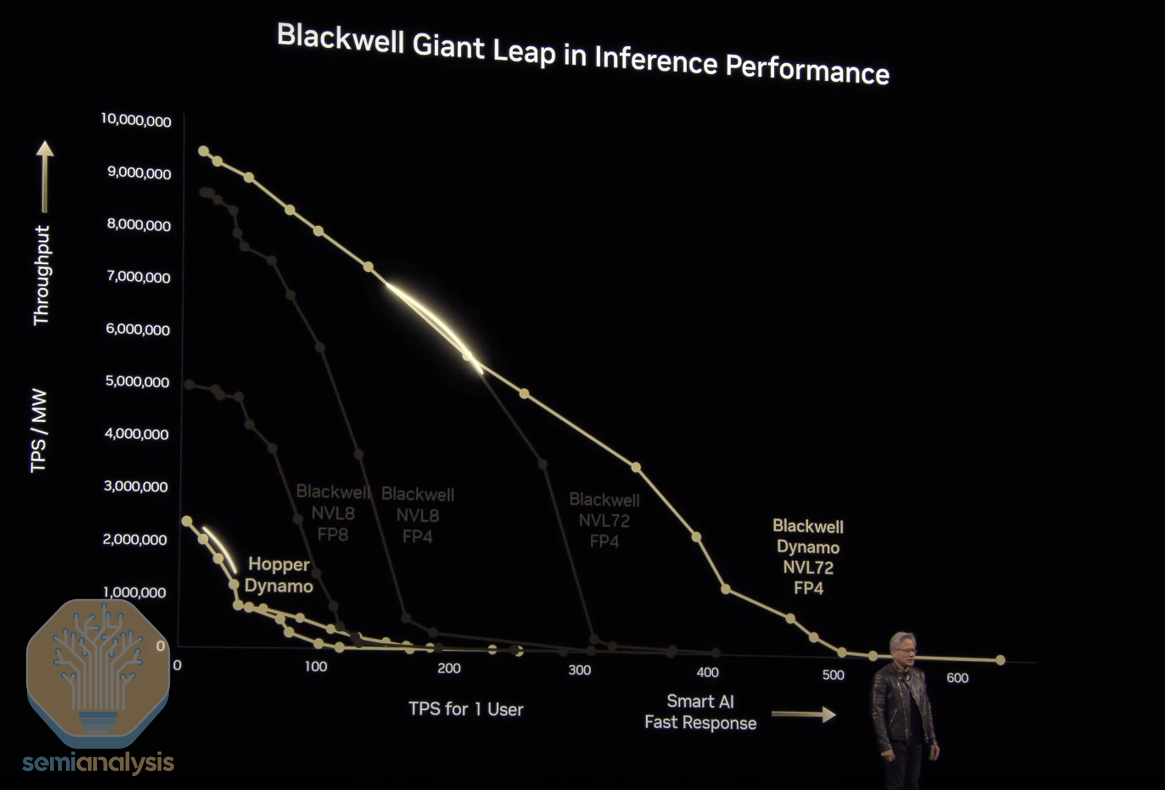
着AI模型复杂度呈指数级增长,推理计算需求正在经历前所未有的"令牌爆炸"现象。NVIDIA最新公布的Blackwell Ultra B300和Rubin架构,通过革命性的硬件创新与软件优化协同,将推理效率提升高达35倍,正在重新定义AI基础设施的经济模型和技术边界。

第一部分:推理令牌爆炸与Jensen定律
当前AI领域正面临三个关键缩放定律的叠加效应:
- 训练前缩放:模型规模持续扩大
- 训练后缩放:微调需求激增
- 推理时间缩放:实时性要求提高
这种趋势导致顶级AI模型单次推理需要处理数十万令牌,每月查询量达数亿次。训练后微调(Post-Training)更需消耗万亿级令牌。NVIDIA通过内部研究显示,现代模型需要100T以上的训练令牌,推理时则需要20倍的令牌量和150倍的计算资源。
Jensen定律正在经历第三次迭代:
- 第一定律:FLOPs计算方式的特殊性
- 第二定律:带宽的双向报价标准
- 第三定律:GPU计数方式的改变(从封装数变为芯片数)
第二部分:Blackwell Ultra B300架构创新
Blackwell Ultra B300代表了NVIDIA在AI加速器领域的最新突破:
核心规格:
- 算力密度比B200提高50%以上
- 每个封装内存容量升级到288GB(12-Hi HBM3E堆栈)
- 带宽维持在8TB/s
设计革新:
- 首次采用可移动SXM模块设计
- 通过减少FP64 ALUs并用FP4单元替代来优化AI负载
- 使用CoWoS-L封装技术提升良率
系统级创新:
- B300 NVL16配置采用16个单芯片封装
- 引入CX-8网卡,InfiniBand吞吐量翻倍至800G
- 移除Astera Labs定时器,部分客户可选PCIe交换机

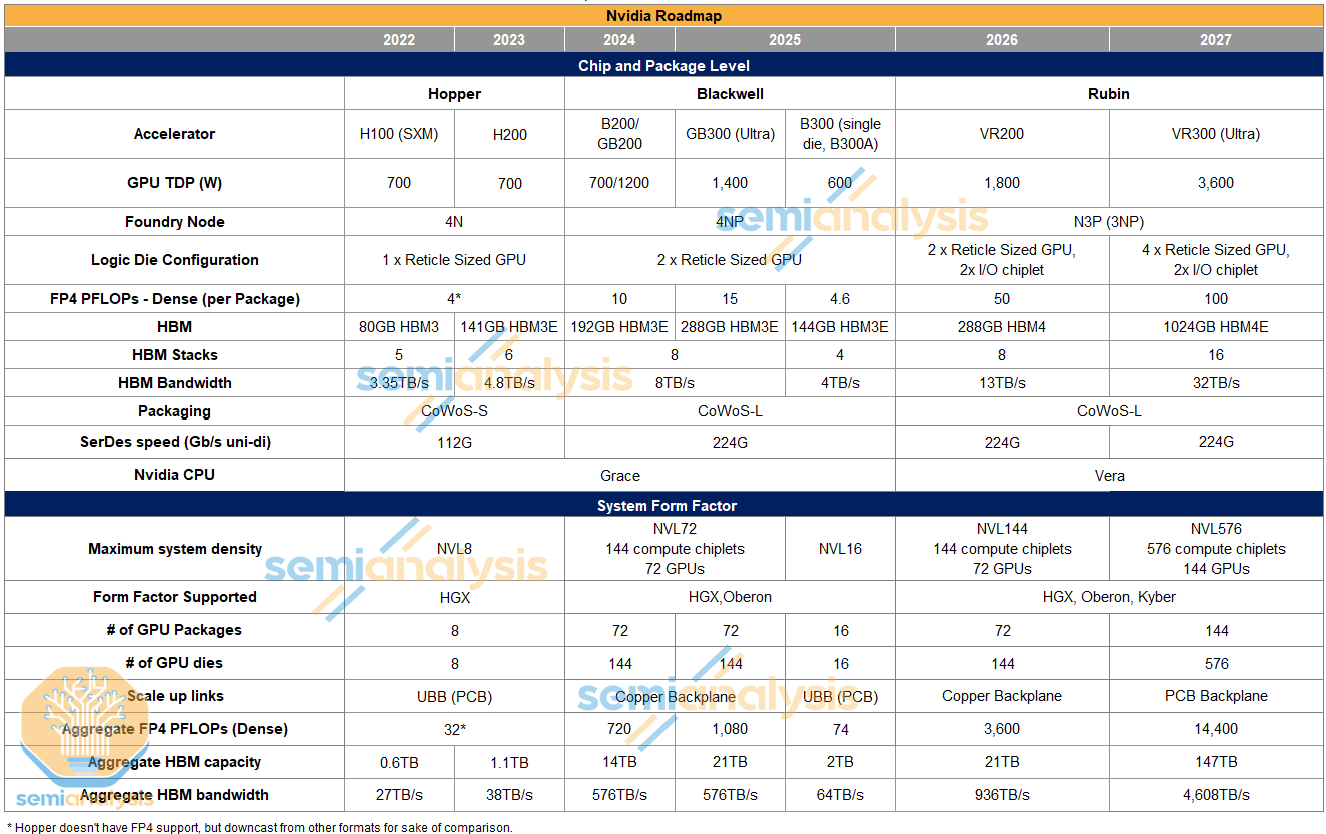
第三部分:Rubin架构前瞻
Rubin架构计划于2026年推出,将带来多项突破性创新:
制程与设计: - 采用台积电3nm工艺
- 双计算芯片+双I/O芯片的创新布局
- 预计TDP达1800W,时钟频率显著提升
性能指标:
- 密集FP4算力达50 PFLOPs(Blackwell的3倍)
- 采用HBM4内存,带宽提升至13TB/s
- NVLink 6速度翻倍至3.6TB/s
超大规模配置:
- Rubin Ultra版本配备16颗HBM4E
- 内存容量突破1TB
- 采用创新的Kyber机架架构

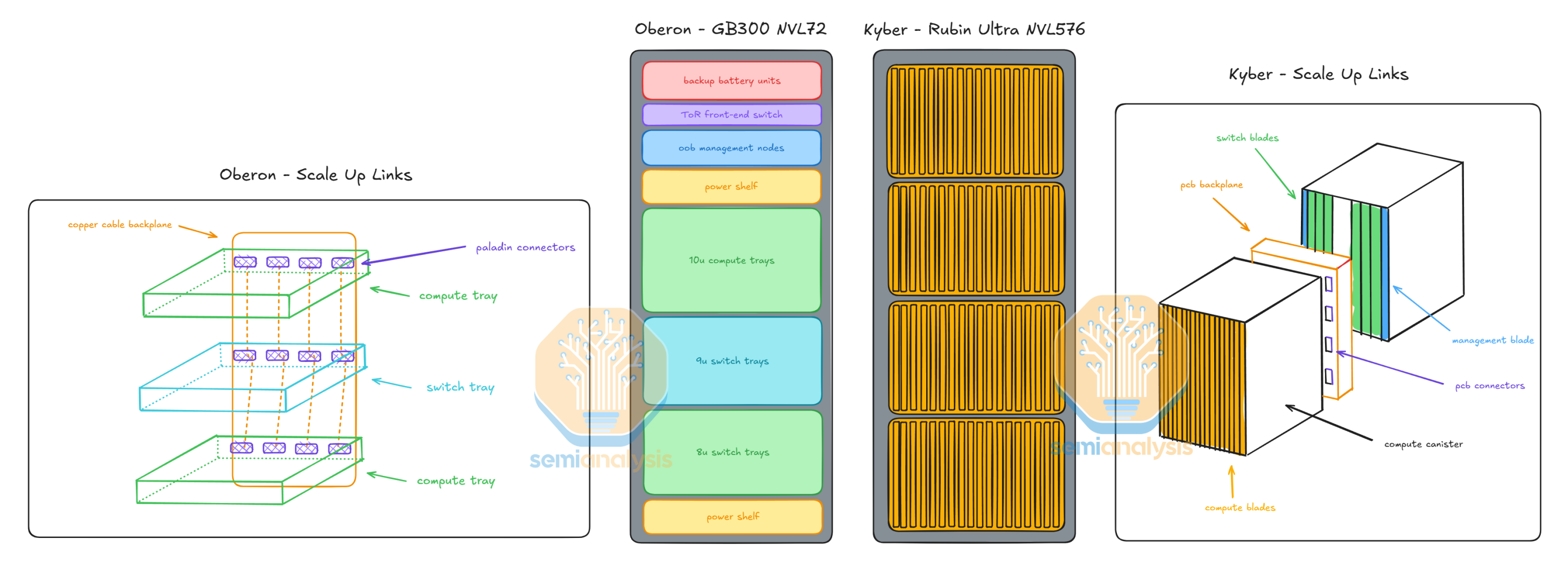
第四部分:Kyber机架架构革命
Kyber机架架构代表了数据中心设计的重大变革:
核心特点: - 计算托盘旋转90度采用刀片式设计
- 每个机架包含四个罐体,每个罐体18个计算刀片
- 支持NVL576配置(144个GPU封装)
互联创新:
- PCB背板替代铜缆背板
- 引入NVSwitch 7芯片
- 支持未来NVL1,152(288个封装)扩展
基础设施影响:
- 独立电源、冷却和交换机机架
- 更高的机架密度和能效比
- 为超大规模AI训练优化
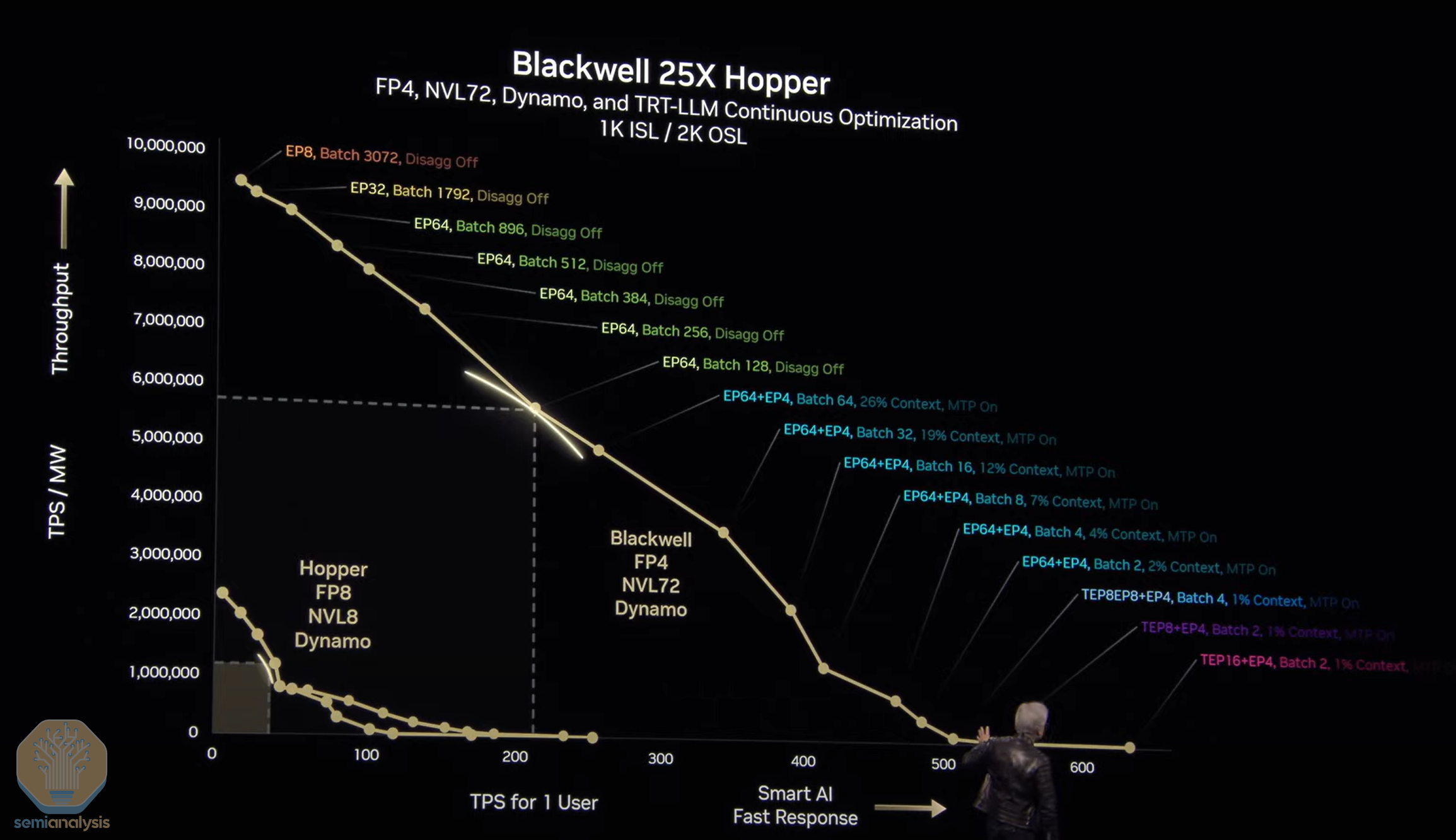
第五部分:软件栈与推理优化
NVIDIA推出Dynamo推理引擎堆栈,包含多项突破性技术:
核心组件: - 智能路由器:动态任务分配
- GPU规划器:自动扩缩容
- NIXL传输引擎:GPU-NIC直连
性能优化:
- 改进的NCCL推理集合通信
- KV缓存卸载管理
- 低延迟算法优化
实际效益:
- 负载均衡效率提升4倍
- 传输延迟降低90%
- 内存占用减少40%
第六部分:市场影响与未来展望
NVIDIA的技术路线图将深刻影响AI产业:
经济模型: - AI总拥有成本(TCO)预计下降60%
- 边缘AI部署门槛大幅降低
- 推理成本降低推动新应用场景
技术演进:
- CPO(共封装光学)技术即将商用
- 超异构计算架构成熟
- 内存层次结构持续优化
产业格局:
- 硬件性能差距可能扩大
- 软件生态优势巩固领导地位
- 数据中心设计范式转变