微软BitNet震撼登场:400MB内存,无GPU也能碾压对手!
微软推出了BitNet b1.58 2B4T,这是一种新型的大型语言模型,旨在通过高效性重新定义人工智能的可能性。与依赖16位或32位浮点数来表示每个权重的传统AI模型不同,BitNet只使用三个离散值:-1、0或+1。这种方法被称为三进制量化,允许每个权重仅存储在1.58位中,从而大大减少了内存使用,使模型能够在标准硬件上轻松运行,而无需依赖高端GPU。

BitNet b1.58 2B4T:技术突破与性能卓越
BitNet b1.58 2B4T由微软的通用人工智能小组开发,包含20亿个参数,这些参数是模型理解和生成语言的内部值。为了弥补其低精度权重,该模型在一个包含4万亿个令牌的大规模数据集上进行了训练,大约相当于3300万本书的内容。这种广泛的训练使BitNet在性能上与其他类似规模的领先模型不相上下,甚至在某些情况下更胜一筹,如Meta的Llama 3.2 1B、Google的Gemma 3 1B和阿里巴巴的Qwen 2.5 1.5B。
在基准测试中,BitNet b1.58 2B4T在各种任务中展现出了强大的性能,包括小学数学问题和需要常识推理的问题。在某些评估中,它甚至超越了竞争对手。
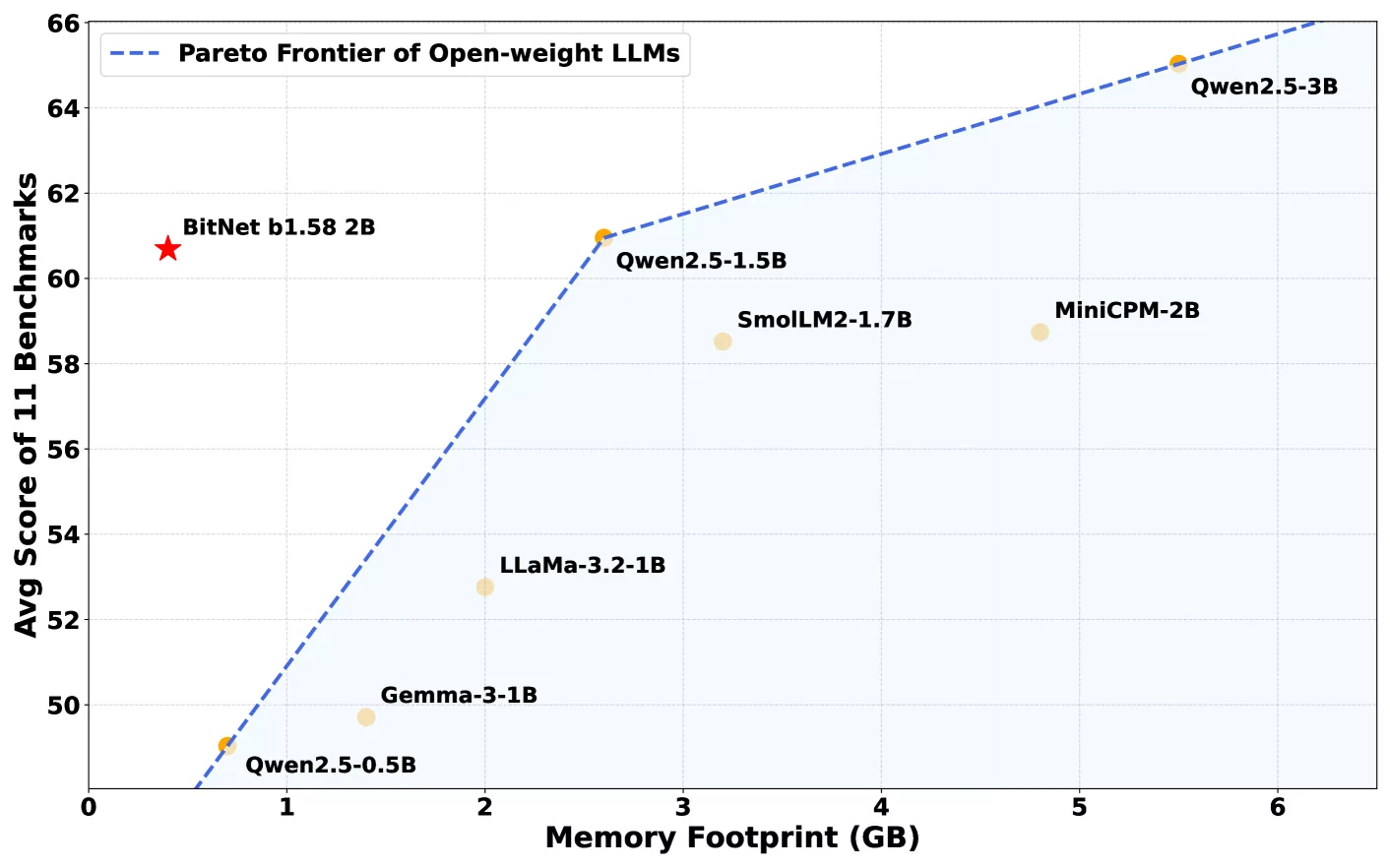
内存效率革命:400MB内存挑战传统
真正让BitNet与众不同的是其内存效率。这款机型只需要400MB内存,不到同类机型通常所需内存的三分之一。因此,它可以在标准CPU上平稳运行,包括苹果的M2芯片,无需依赖高端GPU或专门的AI硬件。
这种效率水平是通过一个名为bitnet.cpp的定制软件框架实现的,该框架经过优化,可以充分利用模型的三进制权重。该框架确保了日常计算设备的快速和轻量级性能。
定制框架:bitnet.cpp引领性能新高度
像Hugging Face的Transformers这样的标准AI库无法提供与BitNet b1.58 2B4T相同的性能优势,因此使用自定义bitnet.cpp框架至关重要。目前,该框架针对CPU进行了优化,但计划在未来的更新中支持其他处理器类型。
降低模型精度以节省内存的想法并不新鲜,但过去的大多数尝试都是在训练后转换全精度模型,这通常是以牺牲精度为代价的。BitNet b1.58 2B4T则采取了一种不同的方法:它只使用三个权重值(-1,0和+1)从头开始训练,从而避免了早期方法中出现的许多性能损失。
能源革命:BitNet开启个人设备AI新时代
这一转变具有重大意义。运行大型人工智能模型通常需要强大的硬件和大量的能源,这些因素推高了成本和环境影响。由于BitNet依赖于极其简单的计算——大部分是加法而不是乘法——它消耗的能量要少得多。微软研究人员估计,它比同类全精度型号节省85%到96%的能源。这可能为直接在个人设备上运行高级人工智能打开大门,而无需依赖基于云的超级计算机。
然而,BitNet b1.58 2B4T也存在一些局限性,如目前只支持特定硬件,需要自定义的bitnet.cpp框架,上下文窗口比最先进的模型要小。但这些局限性也为未来的研究提供了方向。
未来展望
研究人员仍在调查为什么该模型在如此简化的架构下表现如此之好的原因,未来的工作将旨在扩展其功能,包括支持更多的语言和更长的文本输入。