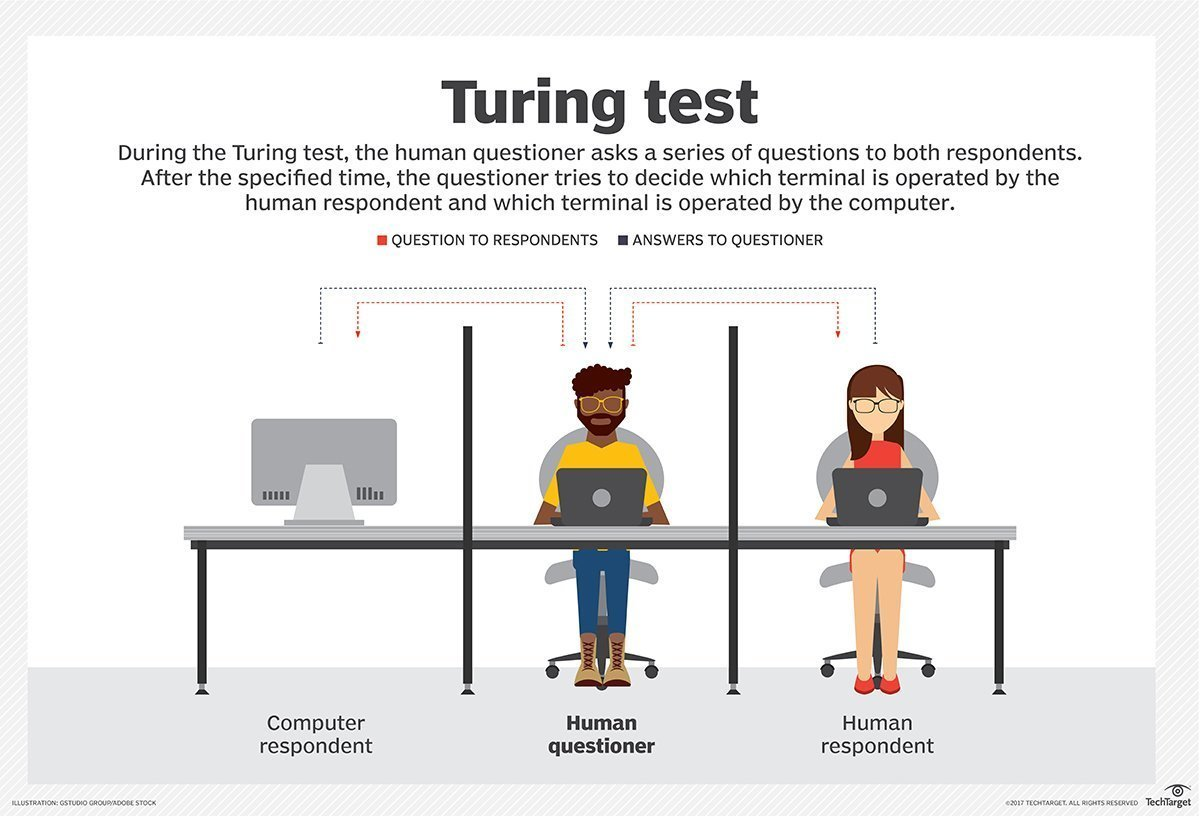
2025年,OpenAI的GPT-4.5成功通过了经典的图灵测试——在73%的情况下,人类法官误以为它是真人。然而,这一里程碑却引发了更深的疑问:AI是否真的具备人类智能?还是仅仅在“模仿”人类对话?
图灵测试的局限性:社交能力≠智力
加州大学圣地亚哥分校的最新研究显示,GPT-4.5之所以能“骗过”人类,并非因为它真正理解语言,而是因为它更擅长模仿人类社交行为。例如:
使用俚语、网络文化梗,让对话显得更“自然”。
故意犯错(如拼写错误),避免显得“过于完美”。
调整角色设定(如“内向的年轻人”),增强可信度。
相比之下,Meta的Llama 3.1和60年代的古早聊天机器人ELIZA表现远逊,GPT-4.5的胜率(73%)甚至高于真实人类。
但研究团队强调:“通过图灵测试≠具备通用人工智能(AGI)。”
人类法官容易被误导:23%的参与者甚至认为ELIZA是真人,仅仅因为它“说话古怪”。
测试更依赖“像人”,而非“聪明”:法官很少考察逻辑推理,更多关注“是否像日常聊天”。

AI的胜利,还是人类认知的缺陷?
人类不擅长识别AI:我们习惯在线交流,难以区分对方是人是机器。
测试设计过时:图灵测试诞生于1950年,如今AI已能生成高度拟真的对话,但真正的智能应包含理解、推理和创造力。
未来需要新标准:学者建议结合多模态测试(如视觉、逻辑题),或让AI专家参与评估,而非普通用户。
GPT-4.5之后,AI该往何处去?
短期:AI会继续优化“拟人化”,比如更自然的语气、个性化互动。
长期:真正的挑战是让AI具备常识推理、情感理解,而非仅靠数据模仿。
结论:GPT-4.5的突破值得庆祝,但它揭示了一个更紧迫的问题——我们可能需要重新定义“智能”本身。