在人工智能算力竞赛的赛道上,高带宽内存(HBM)技术正扮演着愈发关键的角色。从当下热议的 HBM4 到未来十余年后才会登场的 HBM8,下一代 HBM 内存标准的演进路线图已然铺开,其将为 AI GPU 性能带来飞跃式提升,英伟达(NVIDIA)与超威半导体(AMD)等行业巨头正引领这一技术变革的浪潮。
韩国科学技术研究所(KAIST)与太字节互连和封装实验室(Tera)发布的一份新报告,为我们揭开了下一代 HBM 内存技术的神秘面纱。这份冗长的 HBM 路线图,不仅详细阐述了即将到来的 HBM4 的特性,更展望了到 2038 年 HBM5、HBM6、HBM7 以及 HBM8 的宏伟蓝图。
HBM4:开启高性能新时代
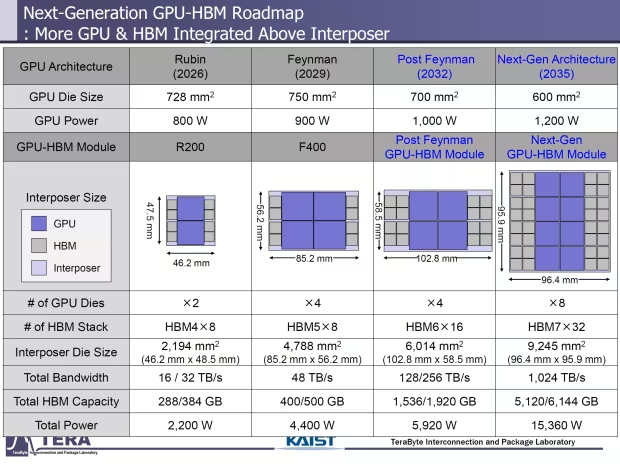
2026 年,HBM4 将正式登上历史舞台,成为 NVIDIA Rubin R100 和 AMD Instinct MI500 AI 芯片的 “动力心脏”。其中,NVIDIA 的 Rubin AI GPU 将配备 8 个 HBM4 站点,而更为强大的 Rubin Ultra 则会将这一数量翻倍至 16 个 HBM4 站点,两款产品均采用双 GPU 芯片横截面设计,Rubin Ultra 凭借更大的横截面,计算密度达到常规 Rubin AI GPU 的两倍之多。
据研究公司透露,NVIDIA 的新 Rubin AI 芯片 GPU 芯片尺寸达 728mm²,单芯片功率最高可达 800W,插入器尺寸为 2194mm²(46.2mm x 48.5mm),将封装 288GB 至 384GB 的 HBM4,内存带宽高达 16 - 32TB / 秒,总芯片功率飙升至 2200W,是当前一代 Blackwell B200 AI GPUs 的两倍。AMD 即将推出的 Instinct MI400 AI 芯片在 HBM4 容量上更胜一筹,拥有 432GB 的 HBM4 容量,内存带宽高达 19.6TB / 秒。
从技术规格来看,HBM4 内存标准将在 2048 位 IO 上实现 8Gbps 的数据速率,每个堆栈的内存带宽为 2TB / 秒,每个芯片的容量为 24Gb,换算下来每个芯片可提供 36 - 48GB 的 HBM4 内存容量,每个堆栈的功率封装为 75W。为应对高功率带来的散热挑战,HBM4 将采用直接到芯片(DTC)液体冷却技术,并使用定制的基于 HBM 的芯片(HBM - LPDDR)。
而 HBM4E 作为更强大的版本,支持高达 10Gbps 的数据速率,每堆栈存储带宽提升至 2.5TB / 秒,每芯片容量可达 32Gb,通过 12 高和 16 高堆栈,能提供 48 - 64GB 的 HBM4 存储容量,每 HBM 封装功率最高达 80W 。
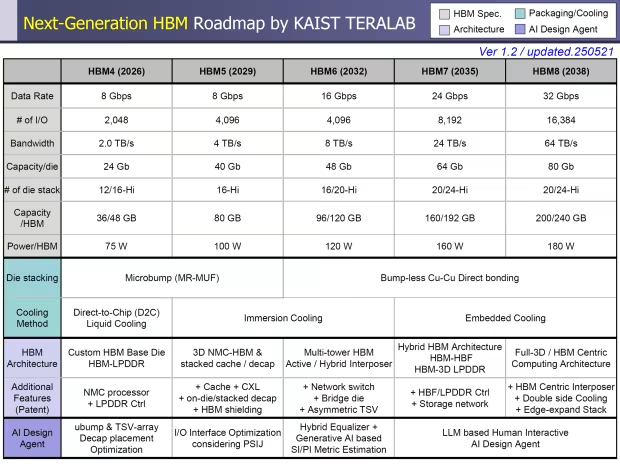
HBM5 至 HBM8:持续突破性能极限
2029 年,NVIDIA 下一代 Feynman AI GPUs 将搭载 HBM5 内存标准首次亮相。届时,IO 通道将提升至 4096 位,每堆栈内存容量达到 4TB / 秒,16 - Hi 堆栈将成为新的行业基线。同时,40Gb DRAM 芯片的应用,使得 HBM5 每堆栈能够驱动高达 80GB 的内存容量,每堆栈功率封装增加到 100W。
HBM5 发布后,HBM6 预计将与 NVIDIA 的下一代 Feynman Ultra AI GPU(尚未确认)一同登场。HBM6 的数据速率将再次翻倍至 16Gbps,拥有 4096 位 IO 通道,带宽跃升至 8TB / 秒,每个 DRAM 芯片容量为 48Gbps。值得一提的是,HBM6 将首次突破 16 - Hi 堆栈的限制,采用 20 - Hi 堆栈设计,每堆叠内存容量提升至 96 - 120GB,每堆叠功率为 120W。此外,HBM5 和 HBM6 内存都将采用浸入式冷却解决方案,HBM6 还将采用多塔 HBM(主动 / 混合)内插器架构,并在研究阶段引入网络交换机、桥接芯片和不对称 TSV 等新功能。
至于 HBM7,其引脚速度将达到每堆栈 24Gbps,拥有更宽的 8192 IO 通道(相比 HBM6 翻倍),每个 DRAM 芯片容量为 64Gb。借助 20 - 24 - Hi 内存堆栈,HBM7 每个堆栈可提供 160 - 192GB 的容量,每堆栈功率封装为 160W。
而最晚在 2038 年发布的 HBM8,数据速率将达到 32Gbps,IO 速率再次翻倍至 16384 个 IO 通道。HBM8 将提供每堆栈 64TB / 秒的带宽,每个 DRAM 芯片容量为 80Gb,每个堆栈内存容量高达 200 - 240GB,每个 HBM 站点的封装功率也提升至 180W。
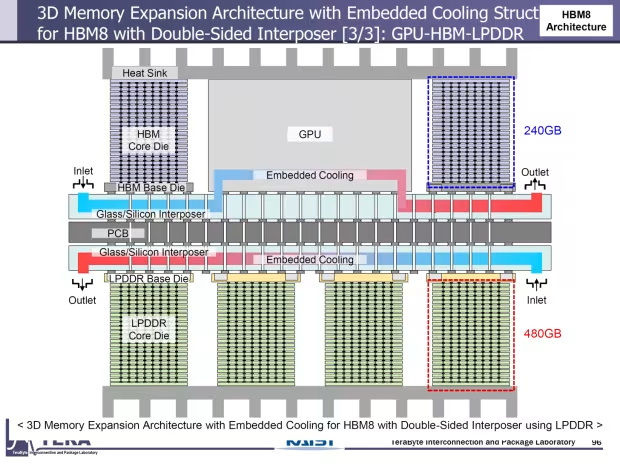
随着 HBM 技术从 HBM4 逐步演进到 HBM8,内存的速度、容量和能效将实现指数级增长。这不仅将为 AI GPU 带来前所未有的性能提升,推动人工智能技术迈向新的高度,还将深刻影响数据中心、高性能计算等众多依赖算力的领域。